Failover là gì? Khi nào thì sử dụng?
The authorization method used in all articles in this blog is:
- free reprint
- non-commercial
- non-derivative
- keep signature
Disclaimer: This blog is welcome to forward, but please keep the original author information!
Facebook: @Ministry.Nd;
Blog address: Ministry's personal blog;
Content is my study, research and summary, if there are similarities, it is an honor!
Ngày nay, trong quá trình triển khai và vận hành, chúng ta thường xuyên được nghe hoặc nhắc đến Failover và Fallback. Cả hai khái niệm này đôi khi sẽ khiến chúng ta nhầm lẫn khi nhắc đến bởi vì:
- cả hai đều hoạt động dựa trên một số kế hoạch dự phòng được xác định trước
- cả hai đều là chiến lược thực hiện để giảm nguy cơ xảy ra lỗi trong một hệ thống
- cả hai đều làm tăng độ phức tạp của hệ thống và chi phí triển khai/ vận hành
- bạn có thể sử dụng một hoặc cả hai trong một kiến trúc hệ thống nhất định
Chúng ta cần phân biệt giữa các thuật ngữ liên quan vì những gì bạn nghĩ có thể không phải là những gì bạn nói và những gì bạn nói có thể không phải là những gì được nghe và những gì được nghe có thể không phải là những gì được thực hiện!
Failover là gì?
Failover là một chiến lược hướng đến giảm thiểu rủi ro để cải thiện service continuity (tính liên tục của dịch vụ) và giảm downtime (thời gian ngừng hoạt động).
Failover hoạt động như thế nào?
Trong một hệ thống đòi hỏi Failover, chúng ta thường quy định và triển khai hai hay nhiều thành phần, hệ thống giống nhau về mặt chức năng, nhiệm vụ. Trong đó, thành phần được làm việc, xử lý trực tiếp được gọi là Primary, và Secondary (đôi khi được gọi là Replicas) quy định cho các thành phần mà có tác dụng để chờ được xử lý, thay thế cho Primary khi Primary bị gián đoạn hoạt động.
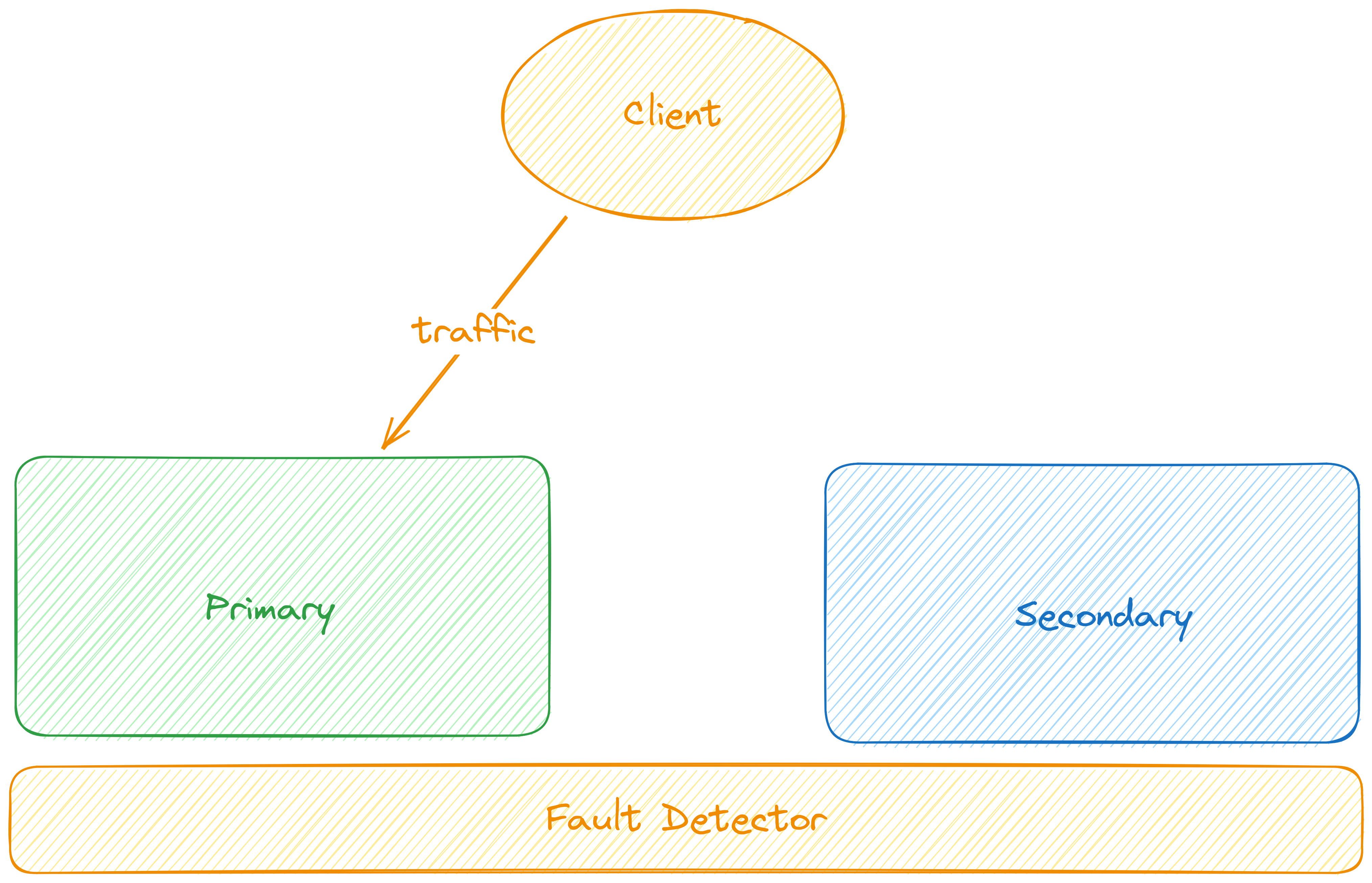
Ngoài ra, để có thể thực hiện chuyển đổi vai trò của primary và secondary với nhau, chúng ta còn yêu cầu cung cấp một thành phần tạm gọi là Fault Detector - với chức năng chính là liên tục monitor trạng thái của hệ thống primary. Khi hệ thống primary được xác định là failed, fault dectetor sẽ tự động làm các công việc để traffic đi vào hệ thống secondary
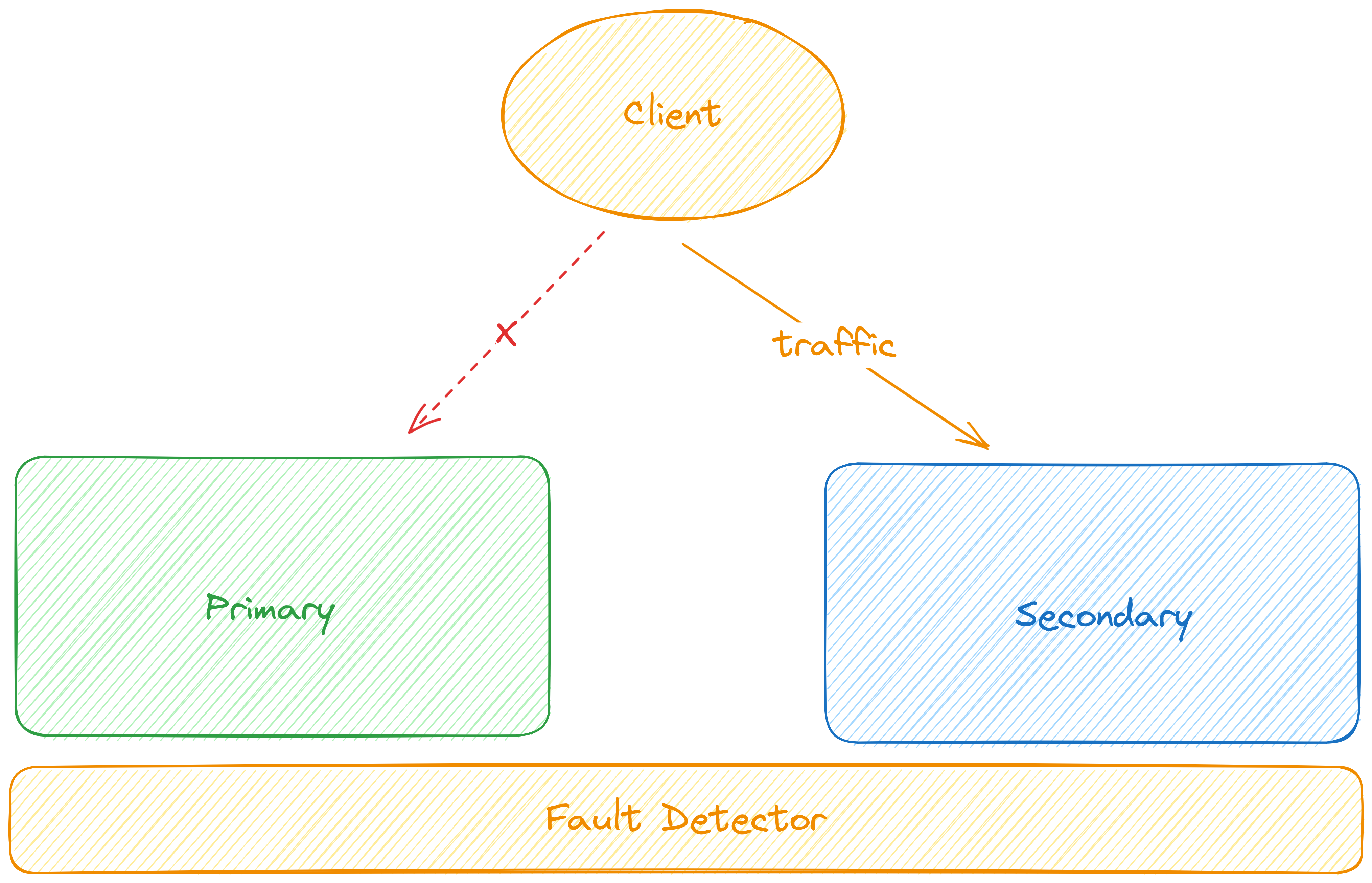
Sau đó, có thể chúng ta sẽ cần phải fix error cho hệ thống primary hoặc thay thế, bổ sung một hệ thống secondary khác để quá trình fault detector luôn luôn có thể diễn ra.
Các đặc điểm chính
Service Continuity: Mục tiêu của failover là giảm thiểu hoặc loại bỏ tác động của lỗi từ client bằng cách chuyển sang hệ thống secondary. Đối với client thì hệ thống vẫn hoạt động như bình thường mà không có sự suy giảm rõ rệt.Redundancy: Failover dựa vào các hệ thống dự phòng (còn được gọi là “backup” aka backup plan). Sự dự phòng này đảm bảo rằng nếu hệ thống primary bị lỗi thì hệ thống secondary có thể tiếp quản một cách liền mạch.Automation: Nếu chỉ cóRedundancythì sẽ không thể đảm bảo được tính sẵn sàng cao, chúng ta thì có thể sẽ không thể kịp xử lý đểfix errornên việc tự động sẽ thường được xuyên là yếu tố được sử dụng và không thể thiếu trong hệ thống có Failover. Bao gồm một vài cơ chế như sau:Automatic Detection: cơ chế phát hiện lỗi tự động monitor hệ thống primary để phát hiện lỗi.Automatic Switch: khi phát hiện thấy lỗi, cơ chế chuyển đổi dự phòng sẽ khởi động và chuyển hướng traffic hoặc khối lượng công việc sang hệ thống secondary. một vài hệ thống sẽ có cơ chế đồng thời chuyển traffic trở lại hệ thống primary khi nó phục hồi.Automated Recovery: đôi khi một quy trình tự động được sử dụng để khôi phục hệ thống primary bằng các kỹ thuật đơn giản. ví dụ: thiết lập khởi động lại, refresh caching, …
Higher Cost: việc dự phòng và tự động hóa làm tăng chi phí tài nguyên và độ phức tạp của hệ thống. chi phí phụ thuộc vào công nghệ sẵn có, loại dịch vụ, lưu lượng traffic và quan trọng nhất là cách người vận hành cảm nhận về độ tin cậy của hệ thống.
Các loại Failovers
Active - Active/ Passive
Đây là 2 cơ chế được dựa trên cơ chế triển khai mô hình hệ thống secondary & primary
-
Active - Active failover: Đây là mô hình triển khai mà có nhiều thành phần primary, trong đó, các thành phần đều hoạt động và đều xử lý các traffic gửi đến. Bằng cách này, một trong số các thành phần primary sẽ không bị quá tải trong khi những thành phần khác chỉ đứng chờ. Đây là cách hoạt động của hầu hết các hệ thống cân bằng tải: phân phối tải giữa các hệ thống tương tự nhau.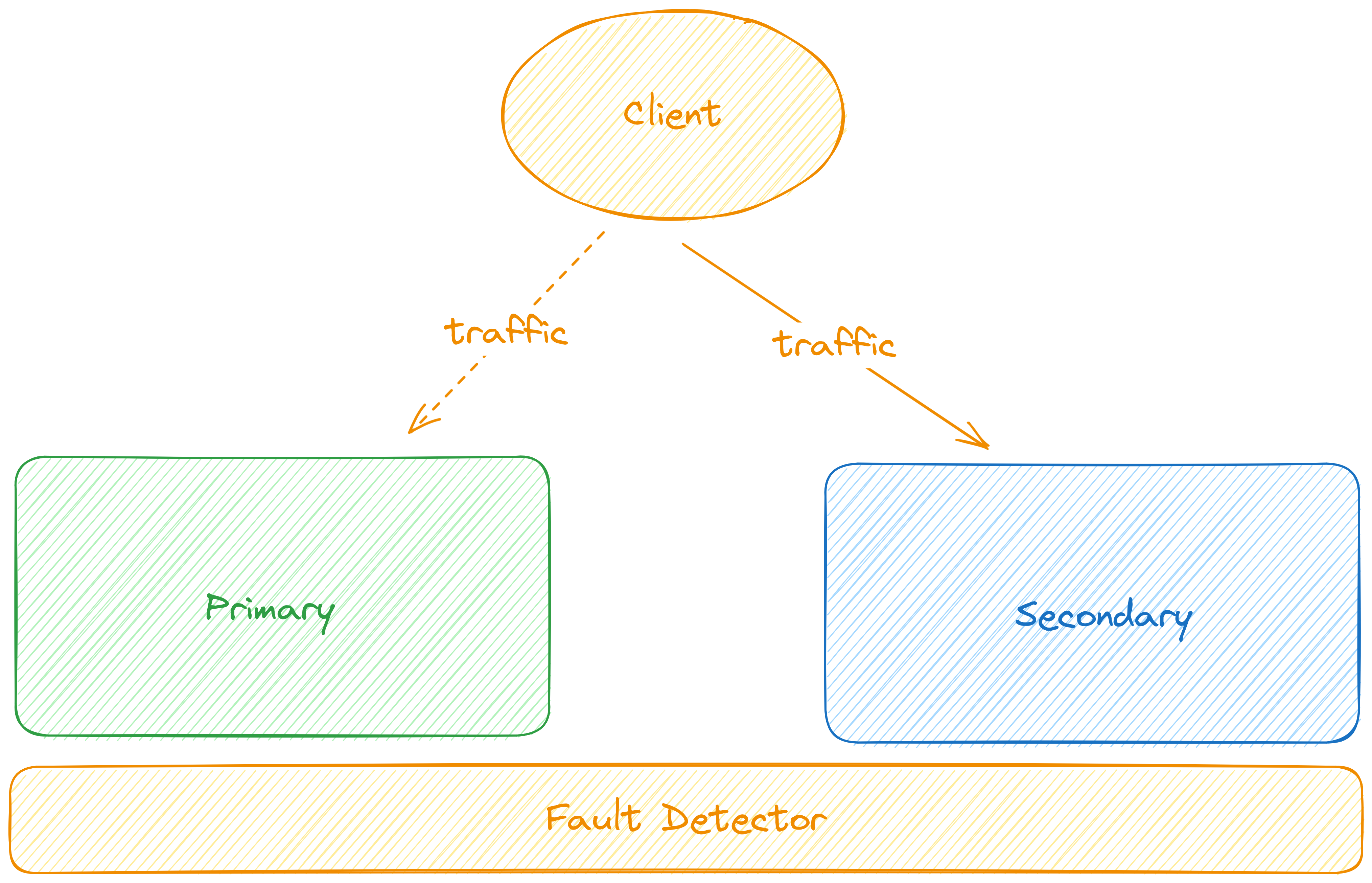
-
Active - Passive failover: Đây là mô hình triển khai mà trong đó các thành phần primary sẽ chịu trách nhiệm xử lý các traffic gửi đến, thành phần secondary sẽ đóng vai trò làstandby node- không xử lý bất kỳ traffic nào.
Dù là mô hình nào chúng ta chọn đi nữa cũng đều dẫn đến việc tốn kém chi phí. Chi phí ở đây bao gồm bất cứ thứ gì có liên quan đến hệ thống như: chi phí triển khai, chi phí vận hành, chi phí dịch vụ liên quan đến người dùng như làm thời gian delay cao hơn, …
Việc có một thiết lập Active - Active hoạt động cũng cho phép thực hiện các thủ thuật thú vị như cải thiện thời gian trễ. ví dụ: bạn có thể gửi cùng một yêu cầu đến nhiều hệ thống và trả lại phản hồi nhanh nhất cho người dùng.
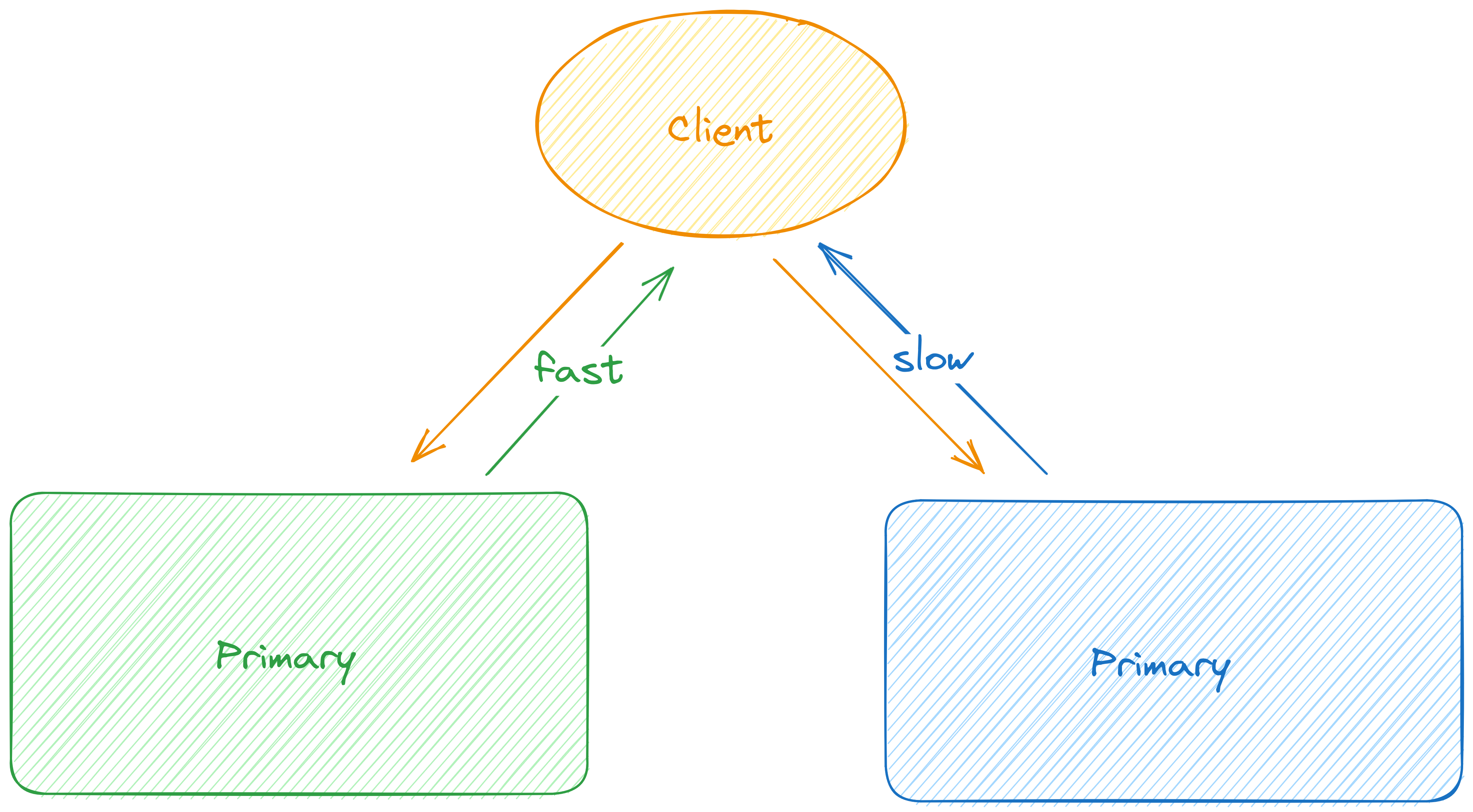
bằng cách này, delay response time của toàn bộ hệ thống sẽ tương đối giống nhau và bằng với response time của primary nhanh nhất.
Hot/ Cold Failover
Có 2 loại cơ chế chuyển traffic từ hệ thống Primary sang Secondary sử dụng trong Failover là Hot & Cold.
- Hot Failover: Hệ thống secondary sẽ sẵn sàng xử lý traffic ngay lập tức. Mô hình Active - Active sẽ luôn luôn là Hot Failover
- Cold Failover: Hệ thống secondary sẽ ở trạng thái
standbyvà thực hiện một số action trước khi có thể sẵn sàng chấp nhận traffic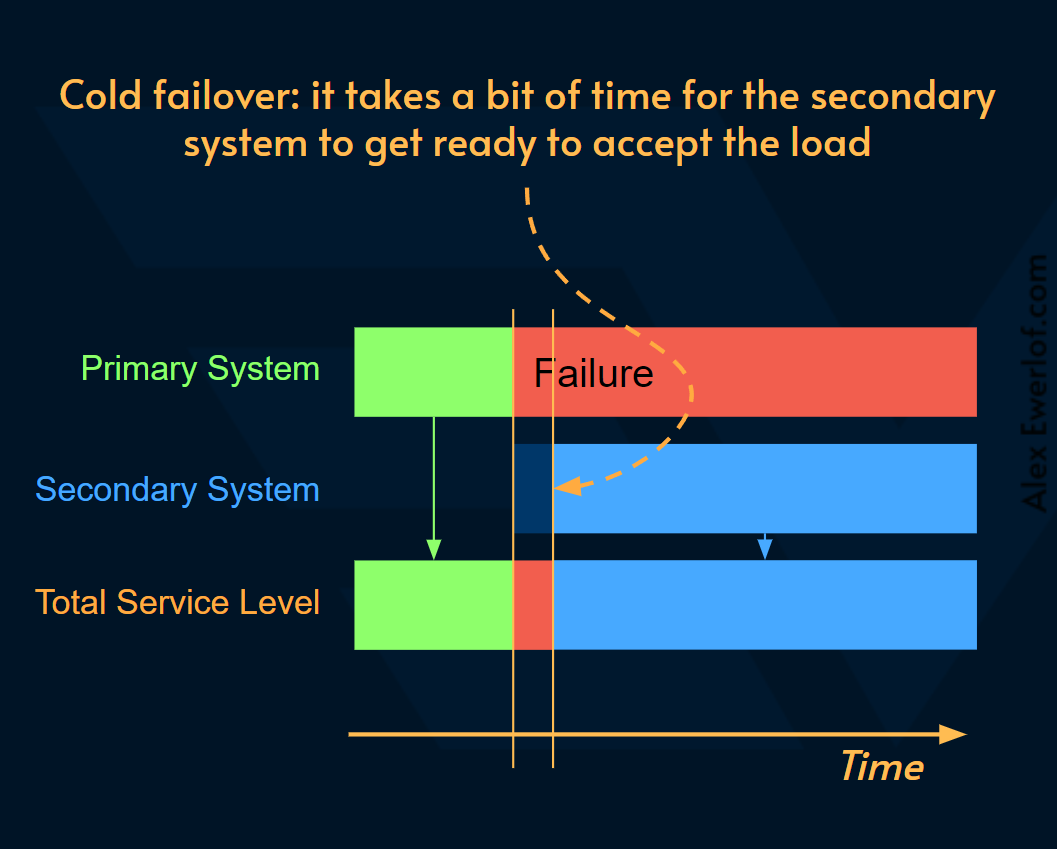
Sự khác nhau chính giữa hai cơ chế này đó chính là thời gian cần để hệ thống secondary có thể xử lý traffic thay thế cho hệ thống primary đã lỗi trước đó.
Cold Failover sẽ làm giảm việc service continuity nhưng chi phí triển khai sẽ rẻ hơn và dễ dàng hơn.
Hard/ Soft Failover
Khi nói đến những gì xảy ra khi hệ thống Primary lỗi, có 2 cơ chế chuyển đổi là Hard & Soft
-
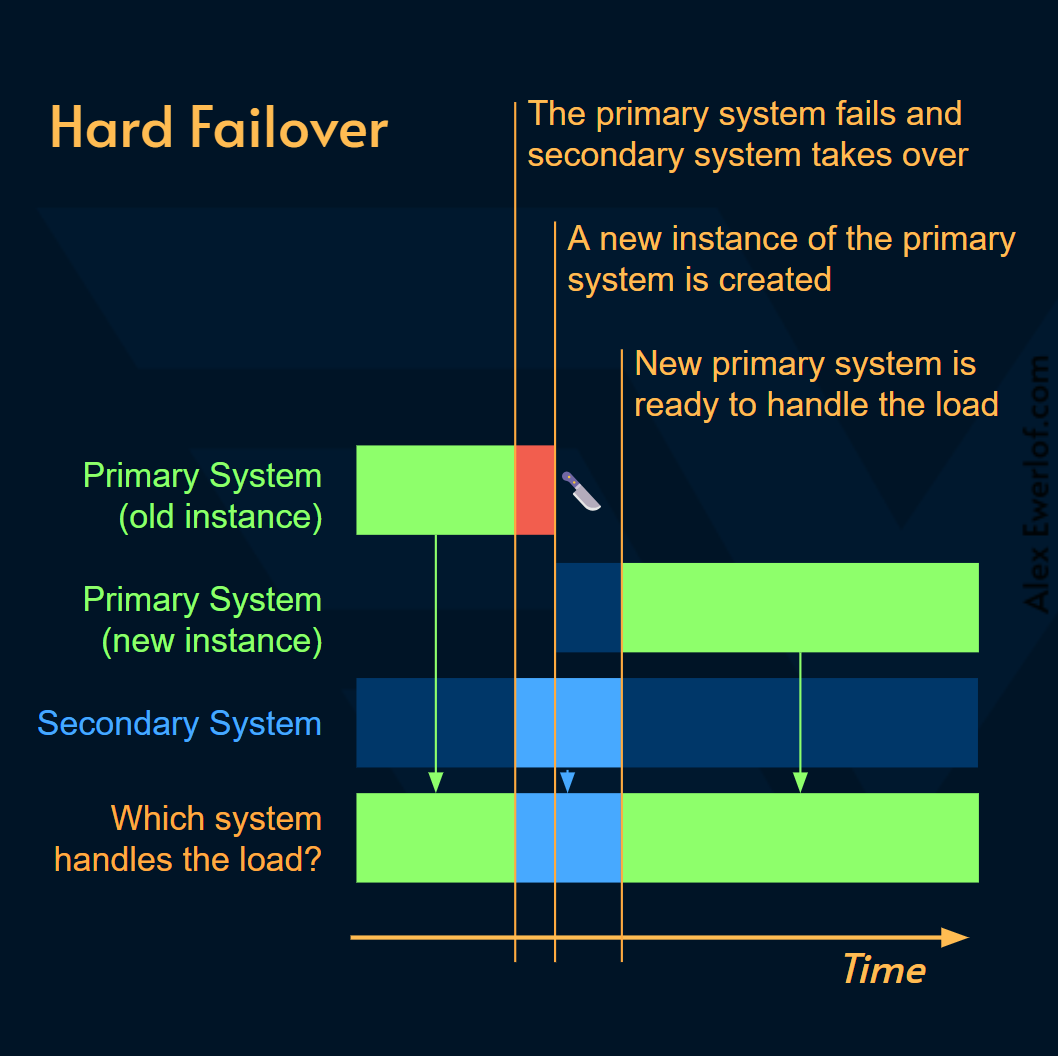
Hard Failover: Shutdown hệ thống primary, đây là một biện pháp khá cực đoan cần được cân nhắc với chi phí xây dựng lại hệ thống primary. Trong quá trình xây dựng lại hệ thống primary, secondary sẽ chịu trách nhiệm xử lý traffic. Đôi khi lựa chọn tốt nhất là giải pháp cũ tốt cho mọi vấn đề: “bạn đã thử tắt và bật lại chưa”? 😄giải pháp này ít phù hợp hơn với các hệ thống như database hay message queues.
-
Soft Failover: để lại hệ thống primary để bạn có thể chẩn đoán và khắc phục sự cố. điều này còn được gọi là
graceful failovervà có thể được thực hiện một cách chủ động trước khi quá muộn để cứu hệ thống khỏi lỗi đó mãi mãi.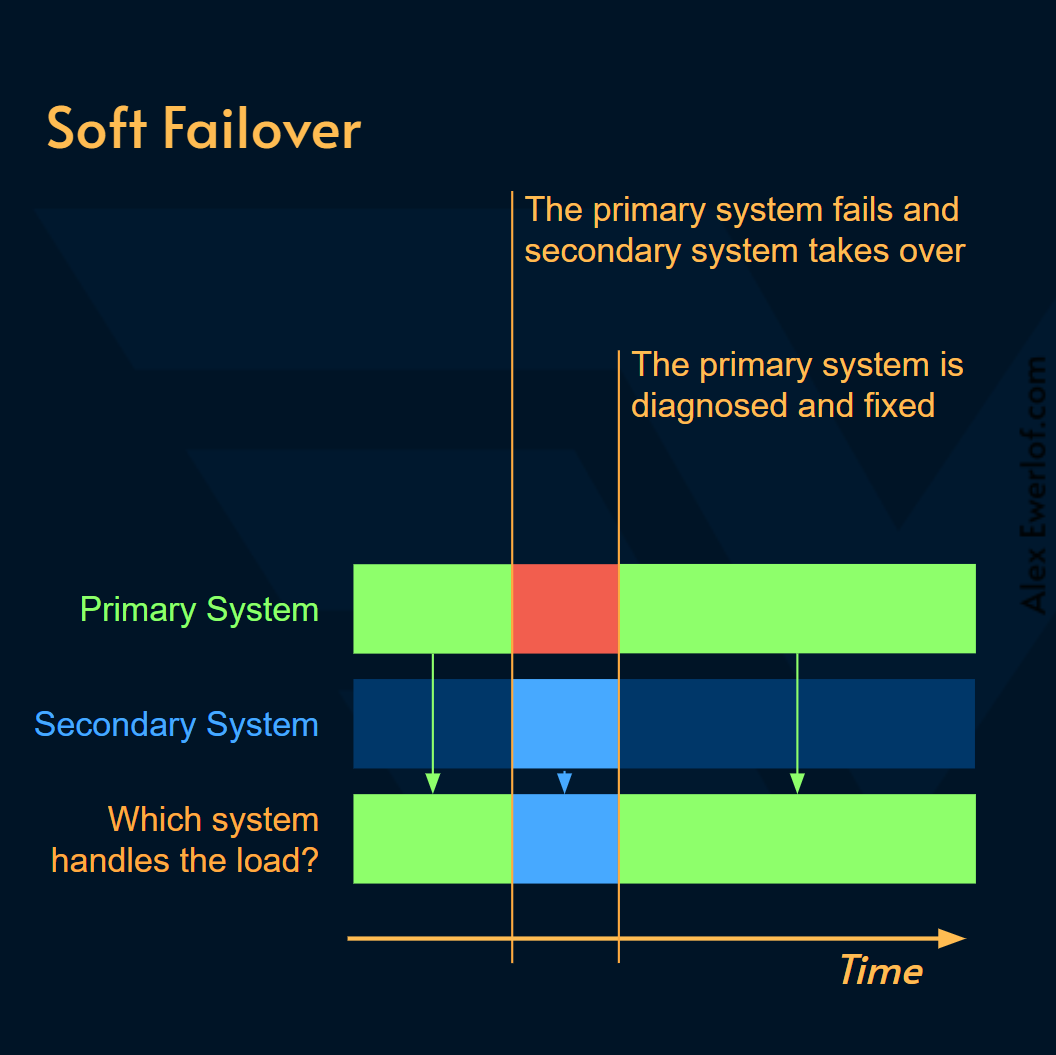
Khi nào thì sử dụng Failover
High Availability được xem là rất quan trọng: nếu hệ thống yêu cầu downtime ở mức tối thiểu hoặc không có downtime và yêu cầu tính khả dụng liên tục thì failover là một chiến lược giảm thiểu rủi ro tốt cần được xem xét.Secondary system is feasible: Theo nguyên tắc chung, stateless services dễ được nhân bản hơn nhưng khi nói đến stateful services (như database), việc thiết lập một hệ thống secondary sẽ phức tạp và tốn kém hơn. Đôi khi hệ thống secondary không khả thi do yêu cầu về pháp lý hoặc công nghệ hiện có.The cost of mitigation is reasonable: Điều này là hiển nhiên dựa trên những gì mà mình đã nói, nhưng điều quan trọng là tránh áp dụng kỹ thuật quá cao vào dịch vụ khi có yêu cầu về lợi nhuận hoặc không phù hợp với cơ chế failover. Đôi khi, rủi ro có thể được chấp nhận vì việc giảm thiểu rủi ro là không đáng kể.
