High Availability Postgres with Patroni/ Spilo (Part 2)
The authorization method used in all articles in this blog is:
- free reprint
- non-commercial
- non-derivative
- keep signature
Disclaimer: This blog is welcome to forward, but please keep the original author information!
Facebook: @Ministry.Nd;
Blog address: Ministry's personal blog;
Content is my study, research and summary, if there are similarities, it is an honor!
Bất kỳ một hệ thống nào, cho dù là Application, Websites, Workers/ Consumers, Database, … khi được xem là quan trọng thì việc cần đảm bảo tính sẵn sàng cao (High Availability) vẫn luôn là tiêu chí được đưa ra mỗi khi triển khai. Ngày hôm nay, mình muốn nói về High Availability cho Postgres bởi vì:
- Postgres chưa hỗ trợ chính thức cho việc High Availability
- Có rất nhiều công cụ 3-party hỗ trợ cho việc xây dựng một hệ thống High Availability cho Postgres
Trong khoảng thời gian gần đây, mình có gặp một bài toán liên quan đến Postgres và yêu cầu của bài toán là xây dựng phương án, giải pháp cho việc Postgres có thể lăn ra dừng hoạt động bất cứ lúc nào. Sau khi tham khảo các ý kiến của anh em System/ Cloud Engineer hay Devops thì mình thấy việc sử dụng Patroni (Spilo) là một giải pháp khá hoàn chỉnh cho việc xây dựng hệ thống High Availability cho Postgres.
Vậy thì cách triển khai và kết nối ở đây như thế nào?
Dưới đây sẽ là nội dung tiếp theo của bài viết High Availability Postgres with Patroni/ Spilo (Part 1)
1. Mô hình triển khai
Dưới đây là mô hình mà mình sẽ thực hiện triển khai:
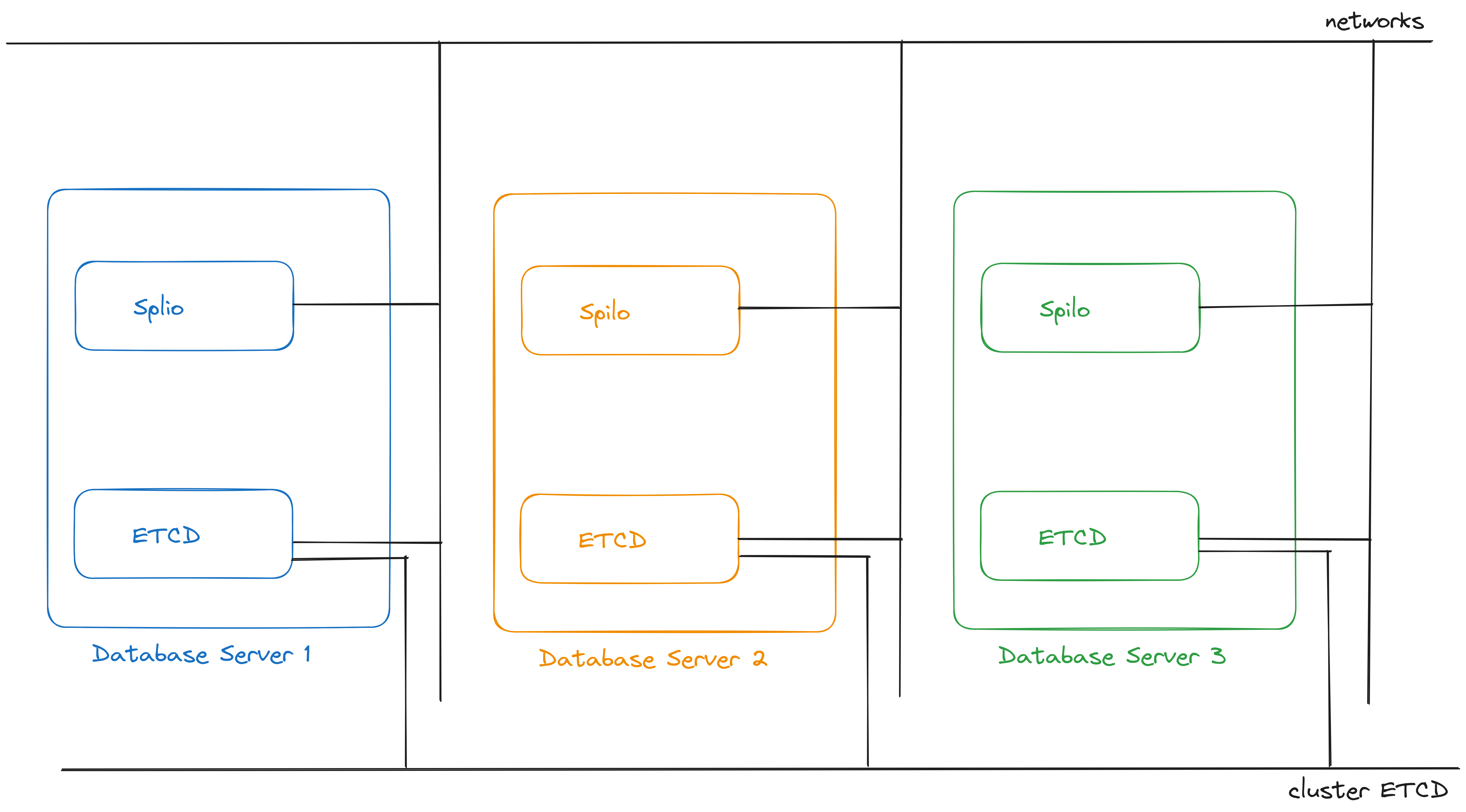
trong đó:
- ETCD là thành phần distributed lock sử dụng cho Patroni và được cấu hình kết nối với nhau như một ETCD cluster
Các thành phần Spilo & ETCD được cài cùng với nhau trên một servers nhằm mục đích cho việc phức tạp hóa mô hình hệ thống và tiết kiệm chi phí, giảm thiểu rủi ro phát sinh trong tương lai.
2. Lợi ích của việc sử dụng Spilo
Đây là một vài lợi ích của việc sử dụng spilo mà chúng ta có thể thấy rất rõ:
- Hỗ trợ các extensions được cài đặt sẵn cho Postgres
- Hỗ trợ các pre/post scripts tự động đối với các action của Patroni
- Hỗ trợ nhiều phương thức backups/ tạo replicas khi thêm node vào cluster Patroni
- Config Crontab/ Backup Schedules
- Vì là chạy trên môi trường Docker nên sẽ có ưu điểm không gây ảnh hưởng đến các package đang cài ở OS
3. Cách thực hiện cấu hình
Trong nội dung phần này, mình sẽ lựa chọn sử dụng với docker-compose để quản lý vì một số lý do sau đây:
- Có thể xem lại chúng ta đã tạo ra container như thế nào, bao gồm các thông tin gì
- Dễ dàng udpate, điều chỉnh các cấu hình cho container
Với thông tin ban đầu là chúng ta có 3 node như sau:
| Node Name | IP Address |
|---|---|
| yanfei-spilo-1 | 10.26.235.206 |
| yanfei-spilo-2 | 10.26.235.157 |
| yanfei-spilo-3 | 10.26.235.75 |
Sau khi chúng ta đã cài đặt docker/ docker-compose và etcd cluster (etcd cluster có thể chạy trên container). Chúng ta thực hiện như sau:
-
Tạo etcd cluster trên các nodes:
- trên node yanfei-spilo-1:
version: "3.0" services: etcd: image: 'quay.io/coreos/etcd:v3.5.9' environment: ALLOW_NONE_AUTHENTICATION: "yes" ETCD_NAME: yanfei-spilo-1 ETCD_ADVERTISE_CLIENT_URLS: http://10.26.235.206:2379 ETCD_INITIAL_ADVERTISE_PEER_URLS: http://10.26.235.206:2380 ETCD_LISTEN_PEER_URLS: http://10.26.235.206:2380 ETCD_LISTEN_CLIENT_URLS: http://10.26.235.206:2379,http://127.0.0.1:2379 ETCD_INITIAL_CLUSTER: yanfei-spilo-1=http://10.26.235.206:2380,yanfei-spilo-2=http://10.26.235.157:2380,yanfei-spilo-3=http://10.26.235.75:2380 ETCD_INITIAL_CLUSTER_TOKEN: etcd-cluster-yanfei-spilo ETCD_INITIAL_CLUSTER_STATE: new ETCD_DATA_DIR: /var/lib/etcd network_mode: host volumes: - /var/lib/etcd:/var/lib/etcd - trên node yanfei-spilo-2:
version: "3.0" services: etcd: image: 'quay.io/coreos/etcd:v3.5.9' environment: ALLOW_NONE_AUTHENTICATION: "yes" ETCD_NAME: yanfei-spilo-2 ETCD_ADVERTISE_CLIENT_URLS: http://10.26.235.157:2379 ETCD_INITIAL_ADVERTISE_PEER_URLS: http://10.26.235.157:2380 ETCD_LISTEN_PEER_URLS: http://10.26.235.157:2380 ETCD_LISTEN_CLIENT_URLS: http://10.26.235.157:2379,http://127.0.0.1:2379 ETCD_INITIAL_CLUSTER: yanfei-spilo-1=http://10.26.235.206:2380,yanfei-spilo-2=http://10.26.235.157:2380,yanfei-spilo-3=http://10.26.235.75:2380 ETCD_INITIAL_CLUSTER_TOKEN: etcd-cluster-yanfei-spilo ETCD_INITIAL_CLUSTER_STATE: new ETCD_DATA_DIR: /var/lib/etcd network_mode: host volumes: - /var/lib/etcd:/var/lib/etcd - trên node yanfei-spilo-3:
version: "3.0" services: etcd: image: 'quay.io/coreos/etcd:v3.5.9' environment: ALLOW_NONE_AUTHENTICATION: "yes" ETCD_NAME: yanfei-spilo-3 ETCD_ADVERTISE_CLIENT_URLS: http://10.26.235.75:2379 ETCD_INITIAL_ADVERTISE_PEER_URLS: http://10.26.235.75:2380 ETCD_LISTEN_PEER_URLS: http://10.26.235.75:2380 ETCD_LISTEN_CLIENT_URLS: http://10.26.235.75:2379,http://127.0.0.1:2379 ETCD_INITIAL_CLUSTER: yanfei-spilo-1=http://10.26.235.206:2380,yanfei-spilo-2=http://10.26.235.157:2380,yanfei-spilo-3=http://10.26.235.75:2380 ETCD_INITIAL_CLUSTER_TOKEN: etcd-cluster-yanfei-spilo ETCD_INITIAL_CLUSTER_STATE: new ETCD_DATA_DIR: /var/lib/etcd network_mode: host volumes: - /var/lib/etcd:/var/lib/etcd
hãy thay các địa chỉ IP tương ứng với các node đang có và thực hiện start trên các node như sau:
bash docker-compose up -d etcd - trên node yanfei-spilo-1:
-
Tạo container database trên các nodes
- Tạo file config cho patroni
/etc/spilo/run/postgres.ymltrên các node như sau:bootstrap: dcs: failsafe_mode: true loop_wait: 15 maximum_lag_on_failover: 33554432 postgresql: parameters: archive_command: test ! -f /var/lib/postgresql/data/wal_archive/%f && cp %p /var/lib/postgresql/data/wal_archive/%f archive_mode: 'on' archive_timeout: 1800s datestyle: iso, mdy default_text_search_config: pg_catalog.english effective_cache_size: 512MB hot_standby: 'on' lc_messages: en_US.UTF-8 lc_monetary: en_US.UTF-8 lc_numeric: en_US.UTF-8 lc_time: en_US.UTF-8 log_destination: stderr log_directory: /var/log/postgresql log_file_mode: 384 log_filename: postgresql.log log_line_prefix: '%t [%p]: [%l-1] %c %x %d %u %a %h ' log_rotation_age: 1d log_rotation_size: 100MB log_timezone: Etc/UTC log_truncate_on_rotation: 'on' logging_collector: 'on' max_connections: 200 max_wal_size: 1GB min_wal_size: 80MB timezone: Etc/UTC update_process_title: 'off' wal_keep_size: 1600MB wal_log_hints: 'on' use_pg_rewind: true use_slots: true retry_timeout: 15 ttl: 45 initdb: - encoding: UTF8 - locale: en_US.UTF-8 - data-checksums post_init: /scripts/post_init.sh "cloud" etcd3: hosts: - 10.26.235.157:2379 - 10.26.235.206:2379 - 10.26.235.75:2379 log: dir: /var/log/postgresql postgresql: authentication: replication: password: <password> username: replicator rewind: password: <password> username: replicator superuser: password: <password> username: postgres basebackup_fast_xlog: command: /scripts/basebackup.sh retries: 2 callbacks: on_role_change: /scripts/on_role_change.sh cloud true connect_address: <IPAddress>:5432 create_replica_method: - basebackup_fast_xlog data_dir: /var/lib/postgresql/data/pgdata listen: '*:5432' name: <node_name> parameters: bg_mon.history_buckets: 120 bg_mon.listen_address: '::' dynamic_shared_memory_type: posix extwlist.custom_path: /scripts extwlist.extensions: btree_gin,btree_gist,citext,extra_window_functions,first_last_agg,hll,hstore,hypopg,intarray,ltree,pgcrypto,pgq,pgq_node,pg_trgm,postgres_fdw,tablefunc,uuid-ossp,pg_partman listen_addresses: '*' log_autovacuum_min_duration: 0 log_checkpoints: false log_connections: false log_disconnections: false max_stack_depth: 7MB pg_stat_statements.track_utility: 'off' port: 5432 shared_buffers: 102MB shared_preload_libraries: bg_mon,pg_stat_statements,pgextwlist,pg_auth_mon,set_user,pg_cron,pg_stat_kcache,pglogical ssl: 'on' ssl_cert_file: /run/certs/server.crt ssl_key_file: /run/certs/server.key unix_socket_directories: /var/run/postgresql wal_buffers: -1 wal_sync_method: fsync pg_hba: - local all postgres trust - local replication postgres trust - local all all trust - local replication replicator trust - host all all ::1/128 md5 - host all postgres 127.0.0.1/32 trust - host all postgres ::1/128 trust - host all postgres all reject - host replication replicator 0.0.0.0/0 md5 - hostnossl all postgres all reject - hostssl all +cloud 127.0.0.1/32 pam - hostssl all +cloud ::1/128 pam - hostssl all +cloud all pam - hostssl all all all md5 - hostssl replication replicator 0.0.0.0/0 md5 pgpass: /run/postgresql/pgpass use_unix_socket: true use_unix_socket_repl: true restapi: authentication: password: <password> username: postgres connect_address: <IPAddress>:8008 listen: :8008 scope: postgres-patroni-cb5o3izcLưu ý:
- bạn cần phải tạo các users/ roles tương ứng trong database với thông tin khai báo ở:
postgresql.authentication. Chi tiết về các config options có thể tìm thấy ở đây. Thông tin về users/ roles trên các node phải giống nhau - Cần thay địa chỉ IP tương ứng của các nodes
IPAddress
- bạn cần phải tạo các users/ roles tương ứng trong database với thông tin khai báo ở:
- Tạo thư mục lưu giữ data như sau:
mkdir -p /var/lib/postgresql/data/pgdata - Tạo container database trên các nodes như sau:
spilo: image: ghcr.io/zalando/spilo-15:3.0-p1 network_mode: host environment: PGDATA: /var/lib/postgresql/data/pgdata PGLOG: /var/lib/postgresql/data/pg_log PGPASSWORD_SUPERUSER: <password> PGUSER_SUPERUSER: postgres PGVERSION: 15 PGHOME: /home/postgres RW_DIR: /run PGROOT: /home/postgres/pgdata/pgroot volumes: - /dev/shm:/dev/shm - /run:/etc/spilo - /var/lib/postgresql:/var/lib/postgresql - /var/lib/postgresql/data:/var/lib/postgresql/data - /var/log/postgresql:/var/log/postgresql - /var/run/postgresql:/var/run/postgresql - /etc/passwd:/etc/passwdvì chạy trong container và postgres có một số config cần phải cấp quyền nên chúng ta sẽ mount trực tiếp thư mục
/dev/shmvà trong container. Các thư mục trên đều chạy dưới quyền của userpostgresnên chúng ta cần mount thêm/etc/passwd
lần lượt trên các node thực hiện start spilo như sau:
bash docker-compose up -d spiloquá trình khởi tạo cluster sẽ được diễn ra tương tự như ở High Availability Postgres with Patroni/ Spilo (Part 1)
- Tạo file config cho patroni
3. Thực hiện kết nối
Như vấn đề đã đặt ra ở bài High Availability Postgres with Patroni/ Spilo (Part 1). Chúng ta cần phải xử lý để applications có thể kết nối đến node primary (leader) mỗi khi có quá trình failover xảy ra. Mình đã tìm hiểu và thấy trong các lib sử dụng để kết nối đến Postgres có một tham số kết nối đó là target_session_attrs đi kèm là các giá trị được mô tả như sau:
- any: Accepts any kind of server, including read-write servers, replicas, and read-only servers.
- prefer-standby: If a read-only replica is available, connect to it. Otherwise, connect to a primary server.
- primary: Connect to a primary server
- read-only: Only accepts read-only servers.
- read-write: Only accepts read-write servers.
- standby: Only accepts standby servers.
Đây là một ví dụ về code trong python:
import psycopg2
hosts = [
<list of host>
]
hosts = ",".join(hosts)
database_name = "postgres"
username = "root"
password = "password"
port = 5432
target_session_attrs = "any"
conn = psycopg2.connect(
database=database_name,
host=hosts,
user=username,
password=password,
port=port,
target_session_attrs=target_session_attrs
)
cur = conn.cursor()
cur.execute("select pg_is_in_recovery(), pg_postmaster_start_time()")
row = cur.fetchone()
print("recovery = ", row[0])
print("time = ", row[1])
chúng ta có thể tùy ý tắt bất kỳ một container nào để có thể test failover và đoạn code trên.
